C++学习笔记
1.基础
格式
- 头文件不用加后缀,如
#include<iostream> - 头文件的后缀
.h、.hpp、.hxx - 源文件的后缀
.cpp、.cxx、.cc <<流插入操作符,c里面是位操作符但这里含义变了,这个叫做运算符重载- IDE中是自动将制表符替换为4个空格
- 函数必须将返回值明确列出,不写的话编辑器默认返回int
- main函数不写return的话,会自动返回一个int值
命名空间/名字空间
不使用using namespace std;因为会导致不同命名空间中同名的在代码中使用时遇到冲突
最好用类似std::cout<<"Hello"<<std::endl
1 | using std::cout; |
名字空间可以嵌套声明
可以定义自己的名字空间类似namespace Myname{......}
名字空间的函数在外部不可见,名字空间的一个作用是隔离标识符的作用范围
错误
| 英 | 中 |
|---|---|
| Syntax Error | 语法错误 |
| Runtime Error | 运行时错误 |
| Logic Error | 逻辑错误 |
输入输出
1 | cin.get() /*读一个字符*/ |
2.C的增强和C++特性
引用
和函数的传参和指针联系在一起
要有本体,引用必须在声明的时候初始化,引用一旦初始化,引用名字就不能再指定给其它变量
对引用的操作是作用在原变量上
1 | /*声明引用类型变量*/ |
声明指针和引用时,*和&要靠近类型而非变量名
1 | float* x; //Not float *x; |
引用是在编译的过程中被处理的,实际上就是在编译层面对程序员进行的一个比较友好的语法,而在实现上是由编译器完成了地址的传递,实质上还是指针
不能简单的理解为一个别名,我们可以这样用,但是要知道底层就是一个指针变量,是要占用内存空间的,和define是不一样的
传参
将引用放在形参的位置,在调用时只需要传递普通变量即可
在被调函数中改变引用的值,原变量也发生变化
3.空指针和动态内存分配
c++11标准引入一个保留字nullptr作为空指针,这样空指针就成为了一个确定的东西
C++中通过运算符new申请动态内存
- new <类型名> (初值) ; //申请一个变量的空间
- new <类型名>[常量表达式] ; //申请数组
如果申请成功,返回指定类型内存的地址;
如果申请失败,抛出异常,或者返回空指针(nullptr)。(C++11)
动态内存使用完毕后,要用delete运算符来释放
- delete <指针名>; //删除一个变量/对象
- delete [] <指针名>; //删除数组空间
new/delete和malloc/free区别
- new/delete是c++中的保留字,不需要头文件,相反,macoll/free在c语言中,需要头文件的支持
- new/delete可以执行构造函数,而macoll却不可以执行
- new/delete可以自动判断字节大小,macoll必须自己指定大小;
- macoll的返回值是void,因此在使用的时候必须进行强类型转换,比如说使用macoll申请一个int类型的空间就需要:(int)macoll(sizeodf(int)),而在new中,则不需要这些东西;
- 安全问题:new是安全的,会自己检测指针是否已经初始化,而macoll不会进行这样的判断
- 返回值问题:macoll的返回值,如果申请成功 就会返回已经申请的内存地址,若申请失败,将会返回空指针:NULL在new中,若申请失败,还可以发出异常
- 对象方面:delete会自己析构函数,但是free却不能完成。new在为对象申请时,可以自己执行构造函数,macoll却不能,如果是用户自定义的对象,macoll不行去申请地址。
- 相比之下:new/delete更像是macoll/free的增强版,但是消耗的的系统资源也会更多
4.bool,列表初始化,强制类型转换
bool
其他和c一样
1 | /*一般以is开头*/ |
列表初始化
能用列表初始化就用列表初始化**,因为不允许窄化,即不允许在赋值时隐式类型转换
1 | /*C++11标准之前的初始化方法*/ |
类型转换
类型转换必须显式声明。永远不要依赖隐式类型转换
语法:static_cast<type> value
5.c++自动类型推导
auto 变量必须在定义时初始化
C++14中,auto可以作为函数的返回值类型和参数类型
定义在一个auto序列的变量必须始终推导成同一类型
1 | auto a4 = 10, a5{20}; //正确 |
如果初始化表达式是引用或const,则去除引用或const语义
1 | int a{10}; int &b = a; |
如果auto关键字带上&号,则不去除引用或const语意
1 | int a = 10; int& b = a; |
初始化表达式为数组时,auto关键字推导类型为指针
1 | int a3[3] = { 1, 2, 3 }; |
若表达式为数组且auto带上&,则推导类型为数组类型
1 | int a7[3] = { 1, 2, 3 }; |
decltype 主要用于泛型编程(模板)
1 |
|
6.内存模型
- 常量区(只读区)
- 全局变量区
- 堆区(放程序员自己分配的空间)(低地址到高地址)
- 栈区(函数的局部变量)(高地址到低地址)
7.常量和指针
常量和指针
常量是程序中一块数据,这个数据一旦声明后就不能被修改了,修改报错
如果这块数据有一个名字,这个名字叫做命名常量;比如 const int A = 42; 其中A就是命名常量;
如果这块数据(这个常量)从字面上看就能知道它的值,那它叫做“字面常量”,比如上面例子中的“42”就是字面常量
代码规范:符号常量(包括枚举值)必须全部大写并用下划线分隔单词。例如:MAX_ITERATIONS, COLOR_RED, PI
1 | const int y = { 42 }; // 这个在C++中叫做常量,在编译期就确定了值 |
1 | const int x = 1; |
*(指针)和 const(常量) 谁在前先读谁 ;* 代表被指的数据,名字代表指针地址
const在谁前面谁就不允许改变
using
1 | using ConstPointer = const unsigned long int *; |
常函数
形式: void fun() const {}
构造函数和析构函数不可以是常函数
特点:①可以使用数据成员,不能进行修改,对函数的功能有更明确的限定;
②常对象只能调用常函数,不能调用普通函数;
③常函数的this指针是const CStu*
8.对象和类
名词
面向对象(Object-Oriented)
对象是一个独一无二的实体
Abstraction(抽象)
Polymorphism(多态)
inheritance(继承)
Encapsulation(封装)
对象有唯一标识,状态和行为
标识:只有一个名字
状态state:数据域
行为behavior:一组函数定义
对象是类(class)的实例(instance)
类同样包含数据域和函数域
1 | class C{ |
特殊函数
构造函数(ctor):在创建对象时被自动调用
析构函数(dtor):在对象被销毁时被自动调用
构造类
类中的东西有公有、私有之分
1 |
|
对象拷贝和声明实现分离
1 | Circle c1; //调用Circle的默认ctor |
成员拷贝
How to copy the contents from one object to the other?(如何将一个对象的内容拷贝给另外一个对象)
(1) use the assignment operator( 使用赋值运算符) : =
(2) By default, each data field* of one object is copied to its counterpart in the other object. ( 默认情况下,对象中的每个*数据域**都被拷贝到另一对象的对应部分)
函数成员没什么好拷贝的
Example: circle2 = circle1;
(1) 将circle1 的radius 拷贝到circle2 中
(2) 拷贝后:circle1 和 circle2 是两个不同的对象,但是半径的值是相同的。( 但是各自有一个radius 成员变量)
匿名对象
Occasionally, you may create an object and use it only once. (有时需要创建一个只用一次的对象)
An object without name is called anonymous objects. (这种不命名的对象叫做匿名对象)
1 | int main() { |
结构体和类
c语言的结构体默认公有
罕见操作
局部类:函数中的类(很少用)
嵌套类:类中类(java比较喜欢)
上机实验
1 |
|
1 |
|
分离
名词解释
C++ allows you to separate class declaration from implementation. (C++中,类声明与实现可以分离)
(1) .h: 类声明,描述类的结构
(2) .cpp: 类实现,描述类方法的实现
FunctionType ClassName :: FunctionName (Arguments) { //… }
其中,:: 这个运算符被称为binary scope resolution operator(二元作用域解析运算符),简称“域分隔符”
内联是为了在编译时会把函数体直接拷贝到调用位置,减少调用开销
1 | class A { |
上机实验
1 | /*main.cpp*/ |
1 | /*function.h*/ |
1 | /*function.cpp*/ |
Avoiding Multiple Inclusion of Header Files
C/C++使用预处理指令(Preprocessing Directives)保证头文件只被包含/编译一次
例1:
1 |
|
例2:
#pragma once // C++03, C90
例3
_Pragma(“once”) // C++11, C99;
对象指针,对象数组和函数参数
对象指针
和c的结构体指针差不多
Object pointers can be assigned new object names(对象指针可以指向新的对象名)
Arrow operator -> : Using pointer to access object members (箭头运算符 -> :用指针访问对象成员)
1 | Circle circle1; |
Object declared in a function is created in the stack.(在函数中声明的对象都在栈上创建); When the function returns, the object is destroyed (函数返回,则对象被销毁).
Circle *****pCircle1 = new Circle{}; //用无参构造函数创建对象
Circle *****pCircle2 = new Circle{5.9}; //用有参构造函数创建对象
//程序结束时,动态对象会被销毁,或者
delete pObject; //用delete显式销毁
1 |
|
对象数组
(1) 声明方式1
Circle ca1**[10];**
(2) 声明方式2
用匿名对象构成的列表初始化数组
Circle ca2**[3] = { // 注意:不可以写成: auto ca2[3]= 因为声明数组时不能用auto**
Circle**{3},**
Circle**{ },**
Circle**{5} };**
(3) 声明方式3
用C++11列表初始化,列表成员为隐式构造的匿名对象
Circle ca3**[3] {** 3.1, {}, 5 };
Circle ca4**[3] = {** 3.1, {}, 5 };
(4) 声明方式4
用new在堆区生成对象数组
- auto* p1 = new Circle[3];
- auto p2 = new Circle[3]{ 3.1, {}, 5 };
- delete [] p1;
- delete [] p2;
- p1 = p2 = nullptr;
无法使用带圆括号的初始值设定项初始化数组,可以选择使用默认构造参数的方法,或者把(1.0)变成{1.0}
1 |
|
1 |
|
1 |
|
函数参数
- Objects as Function Arguments (对象作为函数参数)
You can pass objects by value or by reference. (对象作为函数参数,可以按值传递也可以按引用传递)
(1) Objects as Function Return Value(对象作为函数参数)
// Pass by value
void print( Circle c ) {
/* … */
}
int main() {
Circle myCircle(5.0);
print( myCircle );
/* … */
}
(2) Objects Reference as Function Return Value(对象引用作为函数参数)
void print( Circle& c ) {
/* … */
}
int main() {
Circle myCircle(5.0);
print( myCircle );
/* … */
}
(3) Objects Pointer as Function Return Value(对象指针作为函数参数)
// Pass by pointer
void print( Circle* c ) {
/* … */
}
int main() {
Circle myCircle(5.0);
print( &myCircle );
/* … */
}
- Objects as Function Return Value(对象作为函数返回值)
// class Object { … };
Object f ( /函数形参/ ){
// Do something
return Object(args);
}
// main() {
Object o = f ( /实参/ );
f**(** /实参/ ).memberFunction();
- Objects Pointer as Function Return Value(对象作为函数返回值)
// class Object { … };
Object* f ( /函数形参/ ){
Object* o = new Object(args) // 这是“邪恶”的用法,不要这样做
// Do something
return o;
}
// main() {
Object* o = f ( /实参/ );
f**(** /实参/ )->memberFunction();
// 记得要delete o
允许的用法
// class Object { … };
Object* f ( Object* p, /其它形参/ ){
// Do something
return p;
}
// main() {
Object* o = f ( /实参/ );
// 不应该delete o
实践:
尽可能用const修饰函数返回值类型和参数除非你有特别的目的(使用移动语义等)。
const Object* f(const Object* p, /* 其它参数 */) { }
- Objects Reference as Function Return Value(对象引用作为函数返回值)
// class Object { … };
Object& f ( /函数形参/ ){
Object o {args};
// Do something
return o; //这是邪恶的用法
}
可行的用法1
// class Object { … };
class X {
Object o;
Object f**(** /实参/ ){
// Do something
return o;
}
}
可行的用法2
// class Object { … };
Object& f ( Object& p, /其它形参/ ){
// Do something
return p;
}
// main() {
auto& o = f ( /实参/ );
f**(** /实参/ ).memberFunction();
实践:
用const修饰引用类型的函数返回值,除非你有特别目的(比如使用移动语义)
const Object& f( /* args */) { }
1 |
|
一般来说,能用引用尽量不用指针。引用更加直观,更少出现意外的疏忽导致的错误。
指针可以有二重、三重之分,比引用更加灵活。有些情况下,例如使用 new 运算符,只能用指针
1 |
|
1 |
|
1 |
|
抽象,封装和this指针
数据域采用public的形式有2个问题
- 数据会被类外的方法篡改
- 使得类难于维护,易出现bug
为了能在外部访问私有成员有了访问器和更改器
getter and setter
类抽象与封装
抽象:在研究对象或系统时,为了更加专注于感兴趣的细节,去除对象或系统的物理或时空细节/ 属性的过程
封装:一种限制直接访问对象组成部分的语言机制;一种实现数据和函数绑定的语言构造块
The Scope of Data Members in Class (数据成员的作用域)
- 数据成员可被类内所有函数访问
- 数据域与函数可按任意顺序声明
Hidden by same name (同名屏蔽)
数据域成员的名字和类中函数内部的变量名相同,那么,就近原则,数据域成员被屏蔽
若要访问数据域成员使用关键字this
this->datanama
this特性:特殊的内建指针;引用当前函数的调用对象
避免的简单方法:函数参数设位dataname_
类数据成员的初始化
基本初始化方法
- 在C++03标准中,只有静态常量整型成员才能在类中就地初始化
- C++11标准中,非静态成员可以在它声明的时候初始化
1 | class S { |
类的初始化列表
1 | ClassName (parameterList) |
- 类的数据域是一个对象类型,被称为对象中的对象,或者内嵌对象
- 内嵌对象必须在被嵌对象的构造函数体执行前就构造完成
1 | class Time { /* Code omitted */ } |
Default Constructor 默认构造函数
- 默认构造函数是可以无参调用的构造函数,既可以是定义为空参数列表的构造函数,也可以是所有参数都有默认参数值的构造函数
1 | class Circle1 { |
1 | class Circle2 { |
- 若对象类型成员/内嵌对象成员没有被显式初始化
- 该内嵌对象的无参构造函数会被自动调用
- 若内嵌对象没有无参构造函数,则编译器报错
1 | class X{ |
初始化次序
- 执行次序
就地初始化 > Ctor初始化列表 > Ctor函数体中为成员赋值
- 优先次序
Ctor函数体中为成员赋值 > Ctor初始化列表 > 就地初始化
1 |
|
string类和std::array类
The C++ string Class
- 构造
- 追加
- 赋值
- 位置与清除
- 长度与容量
- 比较
- 子 串
- 搜索
- 运算符
- index: 从index号位置开始
- n: 之后的n个字符
- 用无参构造函数创建一个空字串
string newString; - 由一个字符串常量或字符串数组创建string对象
1 | string message{ "Aloha World!" }; |
1 | /*追加*/ |
数组类
是一个容器类,所以有迭代器(可以认为是一种用于访问成员的高级指针)
可直接赋值
知道自己大小:size()
能和另一个数组交换内容:swap()
能以指定值填充自己: fill()
取某个位置的元素( 做越界检查) :at()
C++数组类是一个模板类,可以容纳任何类型的数据
#include
std::array< 数组 类型, 数组大小> 数组名字;
std::array< 数组 类型, 数组大小> 数组 名字 { 值1, 值2, …};
限制与C风格数组相同
std::array<int , 10> x;
std::array<char , 5> c{ ‘H’,’e’,’l’,’l’,’o’ };
C++17引入了一种新特性,对类模板的参数进行推导 (学完模板才能看懂这句话)
示例:
std::array a1 {1, 3, 5}; // 推导出 std::array<int, 3>
std::array a2 {‘a’, ‘b’, ‘c’, ‘d’}; // 推导出 std::array<char, 4>
c++11断言和常量表达式
常量表达式
断言与C++11的静态断言
- 断言是一条检测假设成立与否的语句
assert : C语言的宏(Macro),运行时检测。
用法:包含头文件
assert( bool_expr ); // bool_expr 为假则中断程序
1 | std::array a{ 1, 2, 3 }; //C++17 类型参数推导 |
assert()依赖于NDEBUG 宏
NDEBUG这个宏是C/C++标准规定的,所有编译器都有对它的支持。
(1) 调试(Debug)模式编译时,编译器不会定义NDEBUG,所以assert()宏起作用。
(2) 发行(Release)模式编译时,编译器自动定义宏NDEBUG,使assert不起作用
如果要强制使得assert()生效或者使得assert()不生效,只要手动 #define NDEBUG 或者 #undef NDEBUG即可。
1 |
|
上面示例的第6行代码中,若assert中断了程序则表明程序出bug了!程序员要重编代码解决这个bug,而不是把assert()放在那里当成正常程序的一部分
- 《代码大全2》:若某些状况是你预期中的,那么用错误处理;若某些状况永不该发生,用断言
1 | int n{ 1 } , m{ 0 }; |
声明与定义
- “声明”是引入标识符并描述其类型,无论是类型,对象还是函数。编译器需要该“声明”,以便识别在它处使用该标识符
- “定义”实例化/实现这个标识符。链接器需要“定义”,以便将对标识符的引用链接到标识符所表示的实体
代理构造
- 一个构造函数可以调用另外的构造函数
1 | class A{ |
A()->A(int)->A(int, int)
- 避免递归调用目标ctor
1 | class A{ |
A()->A(int)->A(int, int)->A()
不可变对象和类
- 不可变对象:对象创建后,其内容不可改变,除非通过成员拷贝
- 不可变类 :不可变对象所属的类
删除set类型函数即可
- 另一种情况:指针成员
让类成为“不可变类”
- 所有数据域均设置为“私有”属性
- 没有更改器函数
- 也没有能够返回可变数据域对象的引用或指针的访问器
不可变对象至表示一个状态。所以线程安全没有同步问题
不可变对象更加易于设计、实现和使用
不可变对象是很优秀的Map key和Set element
不可变性使得编写、使用和解释代码很容易
不可变性是得并行变得容易,因为没有冲突
程序被状态不会发生改变,就算有异常发生
不可变对象的引用可以被缓
实例成员与静态成员
- 在类定义中,关键字 static 声明 不绑定到类实例的成员( 该成员无需创建对象即可访问)
静态数据成员具有静态存储期(static storage duration)或者C++11线程存储期特性
静态存储期:对象的存储在程序开始时分配,而在程序结束时解回收
只存在对象的一个实例
静态存储器对象未明确初始化时会被自动“零初始化(Zero-Initialization)”
在下面的例子中,一旦实例化了Square(创建了Square的对象),每个对象中都有各自的side成员。这个side成员就叫做实例成员
而numberOfObjects只存在一个,是由所有的Square对象共享的,叫做静态成员
1 | class Square { |
析构
- 对象销毁时自动调用
- 不带参数
- 不能有返回值
- 不能重载(因为无参)
友元(c++独有)
存在原因:私有成员无法从类外访问,但有时又需要授权某些可信的函数和类访问这些私有成员
友元函数和友元类:用friend关键字声明友元函数或者友元类
友元的缺点:打破了封装性
1 | class Date { |
深浅拷贝
拷贝构造函数
拷贝构造:用一个对象初始化另一个同类对象
1 | /*声明*/ |
warning:两个对象obj1和obj2已经定义。然后这种形式的语句:
obj1 = obj2;不是调用拷贝构造函数,而是对象赋值
拷贝构造要在定义时赋值
隐式声明的拷贝构造函数
- 一般情况下,如果程序员不编写拷贝构造函数,那么编译器会自动生成一个
- 自动生成的拷贝构造函数叫做“隐式声明/定义的拷贝构造函数
- 一般情况下,隐式声明的copy ctor简单地将作为参数的对象中的每个数据域复制到新对象中
深拷贝
拷贝指针指向的内容
How:
- 自行编写拷贝构造函数,不使用编译器隐式生成的(默认)拷贝构造函数
- 重载赋值运算符,不使用编译器隐式生成的(默认)赋值运算符函数
1 | class Employee { |
浅拷贝
数据域是一个指针,只拷指针的地址,而非指针指向的内容
- 创建新对象时,调用类的隐式/默认构造函数
- 为已有对象赋值时,使用默认赋值运算符
1 | Employee e1{"Jack", Date(1999, 5, 3), Gender::male}; |
上面的代码执行之后,e3.birthday指针指向了 e1.birthday所指向的那个Date对象
天方夜谭:
话说你与你的好基友/蜜友外出探险:
你的好基友/蜜友拣了一神灯。Ta擦擦神灯,一个魔鬼从神灯中冒出来可以实现Ta的两个愿望。Ta说:1. 我要一山洞的财宝;2. 我要打开山洞的钥匙。
你也拣了一个神灯,擦擦神灯,一个魔鬼从神灯中冒出来可以实现你的两个愿望。你说:浅拷贝! 然后魔鬼给了你一把钥匙,能打开你好基友的山洞。。。你还剩下一个愿望。。。但是。。。最后你和你的好基友/蜜友因为争抢财宝而同归于尽
你也拣了一个神灯,擦擦神灯,一个魔鬼从神灯中冒出来可以实现你的两个愿望。你说:深拷贝****! 然后魔鬼给了你另外一个山洞的财宝,给了你打开这个山洞的钥匙。。。。。。。。最后你和好基友/蜜友幸福滴生活在一起
vector类
相当于一个长度可变的数组,vector对象容量可自动增大
要指明数据类型
1 | vector<int> iV {-2, -1, 0}; |
Iterator variables should be called i, j, k etc.(迭代变量名应该用 i, j, k 等)
此外,变量名 j, k应只被用于嵌套循环
C++14: 字符串字面量
C++11“原始/生”字符串字面量
1 |
|
从例子中看出,“Raw String literals”在程序中写成什么样子,输出之后就是什么样子。我们不需要为“Raw String literals”中的换行、双引号等特殊字符进行转义
C++14的字符串字面量
C++14将运算符 “”s 进行了重载,赋予了它新的含义,使得用这种运算符括起来的字符串字面量,自动变成了一个 std::string 类型的对象
1 | auto hello = "Hello!"s; // hello is of std::string type |
1 |
|
s1: 3 “abc”
s2: 8 “abc^@^@def”
编码规范进阶
Any violation to the guide is allowed if it enhances readability.
- 只要能增强可读性,你在编码时可以不遵守这些编程风格指南
The rules can be violated if there are strong personal objections against them.
- 如果你有很好的个人理由的话,可以不遵守这些规范
Variables should be initialized where they are declared.
- 变量应在其声明处初始化
- Conventional operators should be surrounded by a space character. (运算符前后应有空格)
- C++ reserved words should be followed by a white space.(C++保留字后边应有空格)
- Commas should be followed by a white space. (逗号后面跟空格)
- Colons should be surrounded by white space.(冒号前后有空格)
- Semicolons in for statments should be followed by a space character.(for语句的分号后有空格)
文件扩展名:头文件用.h,源文件用 .cpp (c++, cc也可)
类应该在头文件中声明并在源文件中定义,俩文件名字应该与类名相同
类成员变量不可被声明为public
结构化绑定
用于数组
结构化绑定声明是一个声明语句,意味着声明了一些标识符并对标识符做了初始化)在C++17中引入
将指定的一些名字绑定到初始化器的子对象或者元素上
cv-auto &/&&(可选) [标识符列表] = 表达式;
cv-auto &/&&(可选) [标识符列表] { 表达式 };
cv-auto &/&&(可选) [标识符列表] ( 表达式 );
cv-auto: 可能由const/volatile修饰的auto关键字
&/&& 左值引用或者右值引用
标识符列表:逗号分隔的标识符
用于对象数据成员
若初始化表达式为类/结构体类型,则标识符列表中的名字绑定到类/结构体的非静态数据成员上
数据成员必须为公有成员
标识符数量必须等于数据成员的数量
标识符类型与数据成员类型一致
1 | class C { // 可以改用 struct C,然后去掉下面的public属性说明 |
1 | /*auto后跟&,则标识符是数据成员的引用 |
继承
| 继承链上的类的对应叫法 | |
|---|---|
| 基类 / Base Class | 派生类 / Derived Class |
| 父类 / Parent Class | 子类 / Child Class |
| 超类 / SuperClass | 子类 / SubClass |
| 继承 vs 泛化 | |
|---|---|
| 继承/Inherit | 子继承父 |
| 泛化/Generalize | 父泛化子 |
C++11引入final特殊标识符,可以使得类不能被继承
1 | class B final {}; |
编译后的输出是 (Visual Studio)
error C3246: “D”: 无法从“B”继承,因为它已被声明为“final”这是程序输出
继承的优点:
提高了代码的复用性
提高了维护性
让类与类之间产生关系
多态的前提就是继承
继承的缺点:
增强了类之间的耦合
软件开发的原则是高内聚,低耦合
C++11:继承中的构造函数
C++11:派生类不继承的特殊函数
- 析构函数
- 友元函数
调用继承的构造函数
1 | class A { |
若派生类成员也需要初始化,则可以在派生类构造函数中调用基类构造函数
1 | class A { |
继承中的默认构造函数
若基类ctor未被显式调用,基类的默认构造函数就会被调用
Circle(){}=Circle():Shape{}{}
Circle(double r){}=Circle():Shape{}{}
构造链和析构链
构造函数链
构造类实例会沿着继承链调用所有的基类ctor
父先子后
析构函数链
子先父后
继承中的名字隐藏
1 | /*编译器报错*/ |
内部作用域的名字隐藏外部作用域的(同名)名字
1 | /*using 声明语句可以将基类成员引入到派生类定义中*/ |
重定义函数
1 |
|
在基类和派生类中分别定义
多态的概念
广义的多态:不同类型的实体/对象对于同一消息有不同的响应,就是OOP中的多态性
多态性有两种表现的方式
1 | /*重载多态:*/ |
联编(Binding): 确定具有多态性的语句调用哪个函数的过程
静态联编(Static Binding):在程序编译时(Compile-time)确定调用哪个函数
例:函数重载
动态联编(Dynamic Binding):在程序运行时(Run-time),才能够确定调用哪个函数
用动态联编实现的多态,也称为运行时多态(Run-time Polymorphism)
实现运行时多态
HOW
实现运行时多态有两个要素:
- virtual function (虚函数)
- Override (覆写) : redefining a virtual function in a derived class. (在派生类中重定义一个虚函数)
虚函数的传递性:基类定义了虚同名函数,那么派生类中的同名函数自动变为虚函数
1 | class A{ |
调用哪个同名虚函数
- 不由指针类型决定
- 而由指针所指的【实际对象】的类型决定
- 运行时,检查指针所指对象类型
1 | class A{ |
类中保存着一个Virtual function table (虚函数表)
Run-time binding (运行时联编/动态联编)
More overhead in run-time than non-virtual function (比非虚函数开销大)
C++11:使用override和final
override显式声明覆写
C++11引入override标识符,指定一个虚函数覆写另一个虚函数
1 | class A { |
override的价值在于:避免程序员在覆写时错命名或无虚函数导致隐藏bug
final 显式声明禁止覆写
C++11引入final特殊标识符,指定派生类不能覆写虚函数
1 | struct Base { |
struct可与class互换;差别在于struct的默认访问属性是public
访问控制 (可见性控制)
the private and public keywords
To specify whether data fields and functions can be accessed from the outside of the class. (说明数据及函数是否可以从类外面访问)
Private members can only be accessed from the inside of the class (私有成员只能在类内的函数访问)
Public members can be accessed from any other classes. (公有成员可被任何其他类访问)
A protected data field or a protected function in a base class can be accessed by name in its derived classes. (保护属性的数据或函数可被派生类成员访问)
访问属性示例
1 |
|
公有继承
1 | /*公有继承的派生类定义形式*/ |
基类成员 在派生类中的访问属性不变
派生类的成员函数 可以访问基类的公有成员和保护成员,不能访问基类的私有成员
派生类以外的其它函数 可以通过派生类的对象,访问从基类继承的公有成员, 但不能访问从基类继承的保护成员和私有成员
私有继承
1 | /*私有继承的派生类定义形式*/ |
基类成员 在派生类中都变成 private
派生类的成员函数 可以访问基类的公有成员和保护成员,不能访问基类的私有成员
派生类以外的其它函数 不能通过派生类的对象,访问从基类继承的任何成员
保护继承
1 | /*私有继承的派生类定义形:*/ |
基类成员 公有成员和保护成员变成protected,私有成员不变
派生类的成员函数 可以访问基类的公有成员和保护成员,不能访问基类的私有成员
派生类以外的其它函数 不能通过派生类的对象,访问从基类继承的任何成员
抽象类与纯虚函数
抽象类:类太抽象以至于无法实例化就叫做抽象类
抽象函数也叫纯虚函数
成员函数应出现在哪个继承层次
问题:Shape类层次中,getArea()函数放在哪个层次
选择1:放哪儿都行:Shape中或子类中定义getArea()
选择2:强制要求Shape子类必须实现getArea()
抽象函数(abstract functions)要求子类实现它
virtual double getArea() = 0; // 在Shape类中
Circle子类必须实现getArea()纯虚函数才能实例化
包含抽象函数的类被称为抽象类
抽象类不能实例化(创建对象)
动态类型转换
1 | void printObject(Shape& shape) |
dynamic_cast 运算符
(1) 沿继承层级向上、向下及侧向转换到类的指针和引用
(2) 转指针:失败返回nullptr
(3) 转引用:失败抛异常
1 | /*先将Shape对象用dynamic_cast转换为派生类Circle对象然后调用派生类中独有的函数*/ |
Upcasting and Downcasting (向上/向下 转型)
upcasting:将派生类类型指针赋值给基类类型指针
downcasting:将基类类型指针赋值给派生类类型指针
1 | Shape* s = nullptr; |
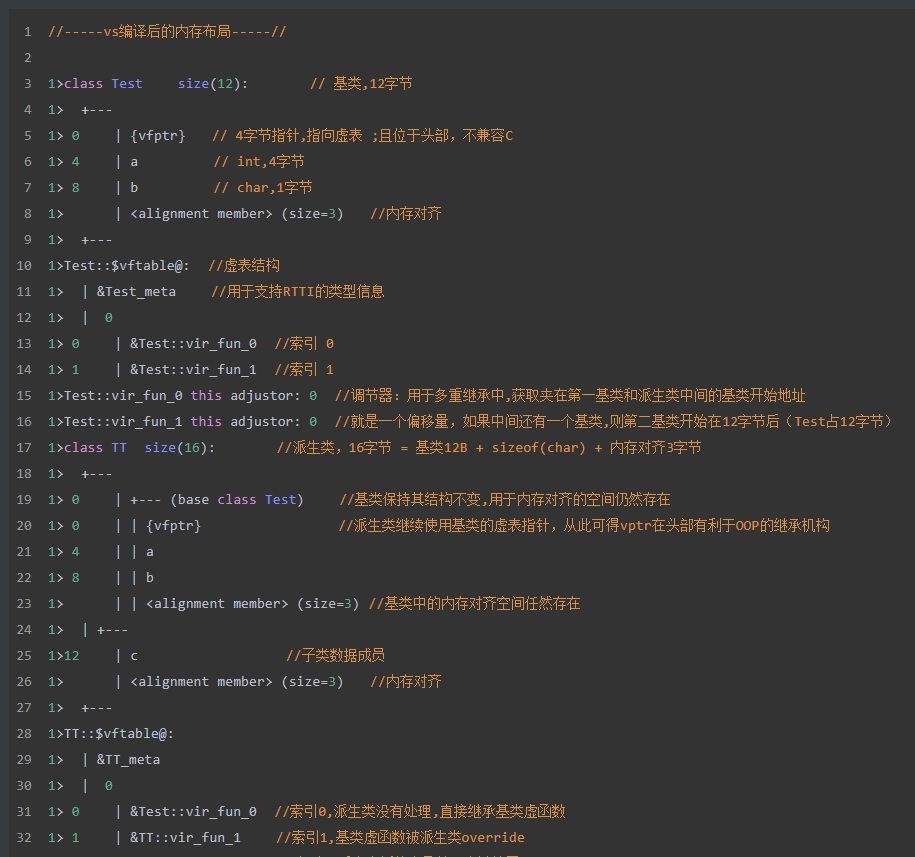
对象内存布局
- 可将派生类对象截断,只使用继承来的信息
- 但不能将基类对象加长,无中生有变出派生类对象
typeid 运行时查询类型的信息
typeid用于获取对象所属的类的信息
- typeid运算符返回一个type_info对象的引用
typeid(AType).name()返回实现定义的,含有类型名称的C风格字符串(char *)
1 |
|
可能的输出(visual studio)
class A
可能的输出(g++)
1A
C++17的文件系统库简介
About std::filesystem
C++17 std::filesystem provides facilities for performing operations on file systems and their components, such as paths, regular files, and directories(标准库的filesystem提供在文件系统与其组件,例如路径、常规文件与目录上进行操作的方法)
Some terms(一些术语)
File(文件):持有数据的文件系统对象,能被写入或读取。文件有名称和属性,属性之一是文件类型
Path(路径):标识文件所处位置的一系列元素,可能包含文件名
路径类:
1 | namespace fs = std::filesystem; |
路径类及操作
path类的成员函数
| 部分重要的成员函数 | 说明 | |
|---|---|---|
| +path(string) | 构造函数 | |
| +assign(string): path& | 为路径对象赋值 | |
| 连接 | +append(type p): path& | 将p追加到路径后。type是string、path或const char*。等价于 /= 运算符;自动添加目录分隔符 |
| +concat(type p): path& | 将p追加到路径后。type是string、path或const char*。等价于+=运算符;不自动添加目录分隔符 | |
| 修改器 | +clear(): void | 清空存储的路径名 |
| +remove_filename(): path& | 从给定的路径中移除文件名 | |
| +replace_filename(const path& replacement): path& | 以 replacement 替换文件名 | |
| 分解 | +root_name(): path | 返回通用格式路径的根名 |
| +root_directory(): path | 返回通用格式路径的根目录 | |
| +root_path(): path | 返回路径的根路径,等价于 root_name() / root_directory(),即“路径的根名 / 路径的根目录” | |
| +relative_path(): path | 返回相对于 root-path 的路径 | |
| +parent_path(): path | 返回到父目录的路径 | |
| +filename(): path | 返回路径中包含的文件名 | |
| +stem(): path | 返回路径中包含的文件名,不包括文件的扩展名 | |
| +extension(): path | 返回路径中包含的文件名的扩展名 | |
| 查询 | +empty(): bool | 检查路径是否为空 |
| +has_xxx(): bool | 其中“xxx”是上面“分解”类别中的函数名。这些函数检查路径是否含有相应路径元素 |
非成员函数
| ** 部分重要的非成员函数** | 说明 | |
|---|---|---|
| operator/( const path& lhs, const path& rhs ) | 以偏好目录分隔符连接二个路径成分 lhs 和 rhs。比如 path p{“C:”}; p = p / “Users” / “batman”; | |
| operator <<, >> (path p) | 进行路径 p 上的流输入或输出 | |
| 文件类型 | s_regular_file( const path& p ): bool | 检查路径是否是常规文件 |
| is_directory( const path& p ): bool | 检查路径是否是目录 | |
| is_empty( const path& p ): bool | 检查给定路径是否指代一个空文件或目录 | |
| 查询 | current_path(): pathcurrent_path( const path& p ): void | 返回当前工作目录的绝对路径(类似linux指令 pwd)更改当前路径为p (类似linux指令 cd) |
| file_size( const path& p ): uintmax_t | 对于常规文件 p ,返回其大小;尝试确定目录(以及其他非常规文件)的大小的结果是由编译器决定的 | |
| space(const path& p): space_info | 返回路径名 p 定位于其上的文件系统信息。space_info中有三个成员:capacity ——文件系统的总大小(字节),free ——文件系统的空闲空间(字节),available ——普通进程可用的空闲空间(小于或等于 free ) | |
| status(const path& p): file_status | 返回 p 所标识的文件系统对象的类型与属性。返回的file_status是一个类,其中包含文件的类型(type)和权限(permissions) | |
| 修改 | remove(const path& p): boolremove_all(const path& p): uintmax_t | 删除路径 p 所标识的文件或空目录递归删除 p 的内容(若它是目录)及其子目录的内容,然后删除 p 自身,返回被删文件及目录数量 |
| rename(const path& old_p, const path& new_p): void | 移动或重命名 old_p 所标识的文件系统对象到 new_p(类似linux指令mv) | |
| copy( const path& from, const path& to ): void | 复制文件与目录。另外一个函数 bool copy_file(from, to) 拷贝单个文件 | |
| create_directory( const path& p ): boolcreate_directories( const path& p ): bool | 创建目录 p (父目录必须已经存在),若 p 已经存在,则函数无操作创建目录 p (父目录不一定存在),若 p 已经存在,则函数无操作 |
Introduction to the Input and Output Classes
between C and C++ (文件操作对比)
| C++ | C | ||
|---|---|---|---|
| **Header File (**头文件) | file input | ifstream (i: input; f:file) | stdio.h |
| file output | ofstream (o: ouput; f:file) | ||
| file input & output | fstream | ||
| **Read/****Write (**读写操作) | **read from file (**读文件) | >>;get(); get(char); get(char*);getline();read(char*,streamsize); | fscanf();fgets(char*, size_t , FILE*);fread(void *ptr, size, nitems, FILE *stream); |
| **write to file (**写文件) | <<;put(char), put(int);write (const char*, streamsize);flush() | fprintf();fwrite(const void *ptr, size, nitems, FILE stream);fputs(const char, FILE *); | |
| **Status test (**状态测试) | eof(); bad(); good(); fail() | feof(); ferror(); |
流
流是一个数据序列
C++的流类主要有五类:
流基类(ios_base和ios)
标准输入输出流类(istream/ostream/iostream)
字符串流类(istringstream/ostringstream)
文件流类(ifstream/ofstream/fstream)
缓冲区类(streambuf/stringbuf/filebuf)
标准输入输出流对象 cin 和 cout 分别是类 istream 和 ostream 的实例
字符串流:将各种不同的数据格式化输出到一个字符串中,可以使用I/O操纵器控制格式;反之也可以从字符串中读入各种不同的数据
带缓冲的输入输出
C++的I/O流是有内部缓冲区的
1 |
|
c = cin.get(void)每次读取一个字符并把由Enter键生成的换行符留在输入队列中
向文件写入数据
ofstrem可向文本文件中写数据

文件已存在,内容被直接清除
1 | output << "LiHua" << " " << 90.5 << endl; |
从文件读数据
ifstrem可从文本文件中读数据
检测文件是否成功打开

若想正确读出数据,必须确切了解数据的存储格式
检测文件是否正确打开的方法
1 | /*open()之后马上调用fail()函数*/ |
检测是否已到文件末尾
1 | /*用eof()函数检查是否是文件末尾*/ |
格式化输出
“设置域宽”控制符
要包含头文件
setw(n) 设置域宽,即数据所占的总字符数
setw()的默认为setw(0),按实际输出
1 | std::cout << std::setw(3) << 'a' |
“设置浮点精度”控制符
setprecision(int n)
1 |
|
“设置填充字符”控制符
setfill(c)
设置填充字符,即“<<”符号后面的数据长度小于域宽时,使用什么字符进行填充
1 | std::cout << std::setfill('1') |
在文件操作中格式化输入/输出
| 控制符 | 用途 |
|---|---|
| setw(width) | 设置输出字段的宽度(仅对其后第一个输出有效) |
| setprecision(n) | 设置浮点数的输/入出精度(总有效数字个数等于n) |
| fixed | 将浮点数以定点数形式输入/出(小数点后有效数字个数等于setprecision指定的n) |
| showpoint | 将浮点数以带小数点和结尾0的形式输入/出,即便该浮点数没有小数部分 |
| left | 输出内容左对齐 |
| right | 输出内容右对齐 |
| hexfloat/defaultfloat | C++11新增;前者以定点科学记数法的形式输出十六进制浮点数,后者还原默认浮点格式 |
| get_money(money)put_money(money) | C++11新增;从流中读取货币值,或者将货币值输出到流。支持不同语言和地区的货币格式https://en.cppreference.com/w/cpp/io/manip/get_moneyhttps://en.cppreference.com/w/cpp/io/manip/put_money |
| get_time(tm, format)put_time(tm,format) | C++11新增;从流中读取日期时间值,或者将日期时间值输出到流。https://en.cppreference.com/w/cpp/io/manip/get_timehttps://en.cppreference.com/w/cpp/io/manip/put_time |
用于输入/输出流的函数
getline()
>>运算符用空格分隔数据
对于文件内容:
Li Lei#Han Meimei#Adam
如下代码只能读入“Li”
1 | ifstream input("name.txt"); |
1 | /*Read in "Li Lei" with member function getline(char* buf, int size, char delimiter)*/ |
1 | /*Read in "Li Lei" with non-member function std::getline(istream& is, string& str, char delimiter)*/ |
get() and put()
1 | /*重载函数*/ |
1 | ostream& put (char c); |
flush()
将输出流缓存中的数据写入目标文件
1 | cout.flush(); // 其它输出流对象也可以调用 flush() |
二进制文件输入与输出
文件的打开模式
fstream与文件打开模式
ofstream : 写数据; ifstream : 读数据
fstream = ofstream + ifstream
创建fstream对象时,应指定文件打开模式
| Mode(模式) | Description(描述) |
|---|---|
| ios::in | 打开文件读数据 |
| ios::out | 打开文件写数据 |
| ios::app | 把输出追加到文件末尾。app = append |
| ios::ate | 打开文件,把文件光标移到末尾。ate = at end |
| ios::trunc | 若文件存在则舍弃其内容。这是ios::out的默认行为。trunc = truncate |
| ios::binary | 打开文件以二进制模式读写 |
模式组合
1 | //Open Mode的定义 |
1 | //几种模式可以组合在一起 |
1 | stream.open("name.txt", ios::out | ios::app); |
二进制输入输出简介
文本文件与二进制文件
都按二进制格式存储比特序列
text file:解释为一系列字符
binary file:解释为一系列比特
*Windows文件的换行(CRLF) vs nix文件的换行(LF)
在Windows上,’\n’输出到文件中会自动编码为’\r’ ‘\n’ 两个字符
在*nix上,’\n’ 字符输出到文件中不变
文本模式的读写是建立在二进制模式读写的基础上的,只不过是将二进制信息进行了字符编解码
二进制读写无需信息转换
| ** Text I/O (文本模式)** | Binary I/O function:(二进制模式) | |
|---|---|---|
| 读 | operator >>; get(); getline(); | read(); |
| 写 | operator <<; put(); | write(); |
如何实现二进制读写
write函数
ostream& write( const char* s, std::streamsize count )
1 | /*可直接将字符串写入文件*/ |
如何将非字符数据写入文件
先将数据转换为字节序列,即字节流
Write the sequence of bytes to file with write() (再用write函数将字节序列写入文件
如何将信息转换为字节流
reinterpret_cast运算符
将一种类型的地址转为另一种类型的地址
将地址转换为数值,比如转换为整数
语法: reinterpret_cast
address是待转换的数据的起始地址
dataType是要转至的目标类型
(对于二进制I/O来说,dataType是 char*)
1 | long int x {0}; |
read成员函数
prototype (函数原型)
istream& read ( char* s, std::streamsize count );
1 | // 读字符串 |
1 | // 读其它类型数据(整数),需要使用 *reinterpret_cast* |
文件位置指示器
fp
文件由字节序列构成
一个特殊标记指向其中一个字节
读写操作都是从文件位置指示器所标记的位置开始
打开文件,fp指向文件头
When you read or write data to the file, the file pointer moves forward to the next data item. (读写文件时,文件位置指示器会向后移动到下一个数据项
随机访问文件
随机访问意味着可以读写文件的任意位置
我们能知道文件定位器在什么位置
我们能在文件中移动文件定位器
Maybe we need two file positioners : one for reading, another for writing
| · | **For reading (**读文件时用) | **For writing(**写文件时用) |
|---|---|---|
| 获知文件定位器指到哪里 | tellg(); tell是获知,g是get表示读文件 | tellp(); tell是获知,p是put表示写文件 |
| 移动文件定位器到指定位置 | seekg(); seek是寻找,g是get表示读文件 | seekp(); seek是寻找,p是put表示写文件 |
seek的原型
1 | xxx_stream& seekg/seekp( pos_type pos ); |
| seekdir 文件定位方向类型 | 解释 |
|---|---|
| std::ios_base::beg | 流的开始;beg = begin |
| std::ios_base::end | 流的结尾 |
| std::ios_base::cur | 流位置指示器的当前位置;cur = current |
例子
解释
seekg(42L);
将文件位置指示器移动到文件的第42字节处
seekg(10L, std::ios::beg);
将文件位置指示器移动到从文件开头算起的第10字节处
seekp(-20L, std::ios::end);
将文件位置指示器移动到从文件末尾开始,倒数第20字节处
seekp(-36L, std::ios::cur);
将文件位置指示器移动到从当前位置开始,倒数第36字节处
运算符与函数
与对象一起用的运算符
1 | /*string类:使用“+”连接两个字符串*/ |
1 | /*array 与 vector类:使用[] 访问元素*/ |
1 | /*path类:使用“/”连接路径元素*/ |
运算符与函数的异同
运算符可以看做是函数,只是运算符编辑器要进一步解析,而函数可以直接调用
不同之处
语法上有区别
3 * 2 //中缀式
* 3 2 //前缀式
multiply ( 3, 2) ; //前缀式
3 2 * //后缀式(RPN)
不能自定义新的运算符 (只能重载)
3 ** 2 // C/C++中错误
pow(3, 2) // 3的平方
函数可overload, override产生任何想要的结果,但运算符作用于内置类型的行为不能修改
multiply (3, 2) // 可以返回1
3 * 2 // 结果必须是6
函数式编程语言的观念
一切皆是函数
Haskell中可以定义新的运算符